This article is a translation of Japanese ver.
Original ver. is here*1.
Hi, this is chang.
Today, I tried to make artificial intelligence learn bike-road race.
Win or...???
0. Bike road race
Not so many people have interests in bike road race in Japan, but it is very popular in Europe, next to football and F1.
About 10 years ago, I was attracted to the sports.
Although I cannot write the whole attraction of the sports here, I have to explain a topic:
slipstream.
In short, this is the phenomena that you can easily go fast by following others.
Is is also called as drafting.
If a road bike is well greased up, friction generated with wheel rotations is very small.
It means that you ride against air resistance.
When you ride at 40 km/h or faster, you can feel that strong wind pushes your body back.
If you run behind another person, the other takes the resistance from the wind instead.
So you can run easily.
According to the paper introduces in the article*2,
group ride with two persons and three persons reduce 35.6% and 47.8% of power consumption, respectively.
This one introduces the simulation of fluid mechanics*3.
Because of the slipstream, you have to be clever if you want to win bike races.
You have to make use of rivals' power to save your energy.
This video*4 is good example.
The eventual winners always hide behind others until the very last of the race and rush full gas at the goal sprint.
I modified the sample that I had written before*5 for bike road race.
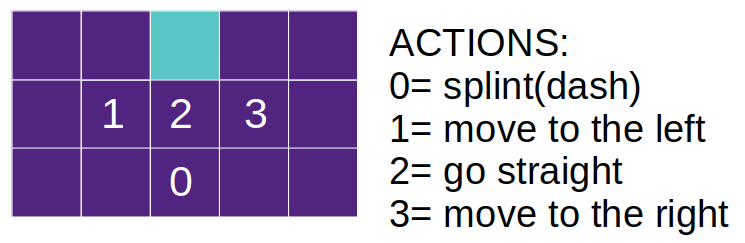
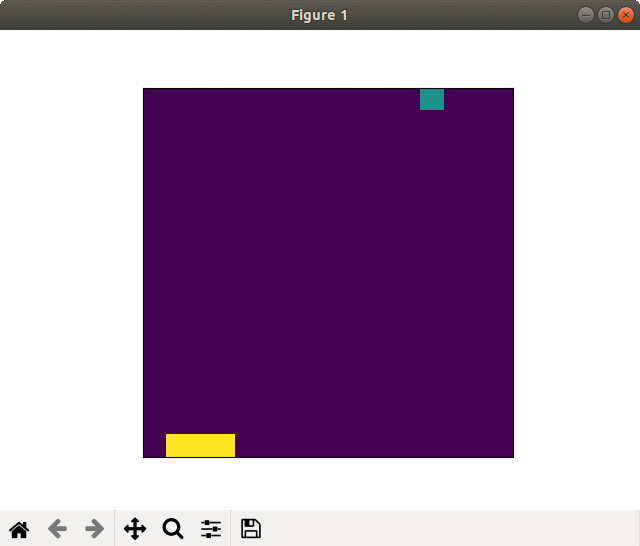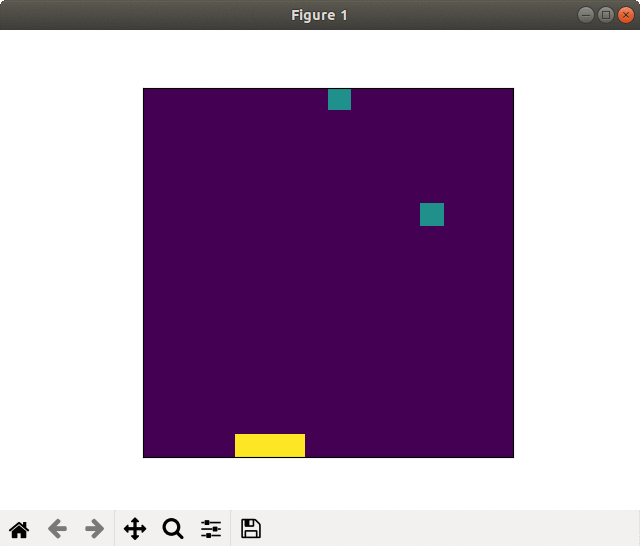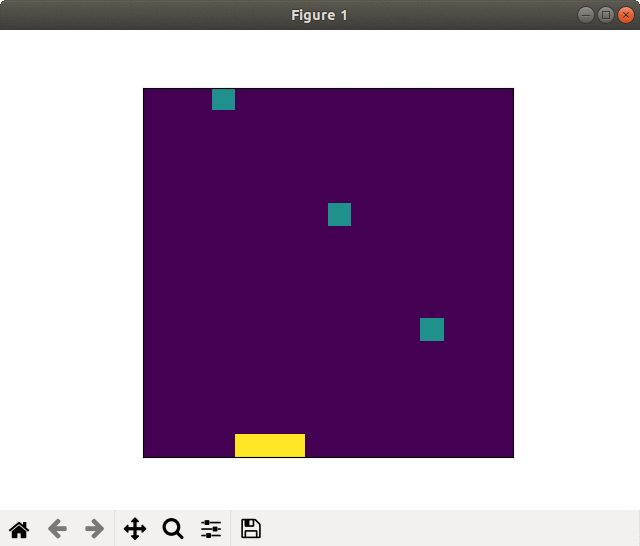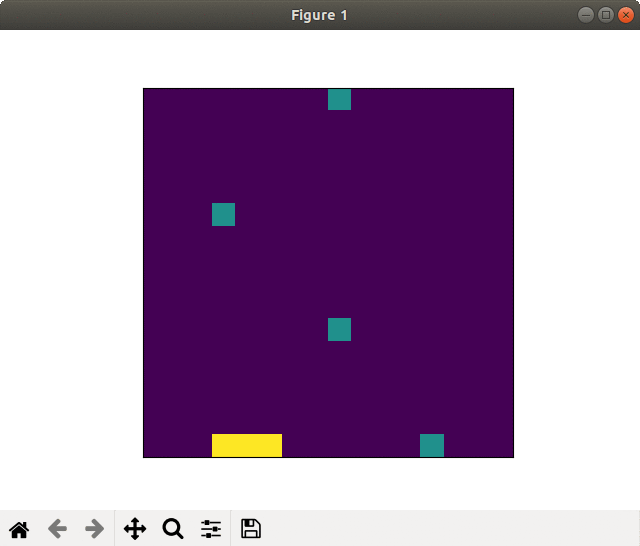
(1) Field
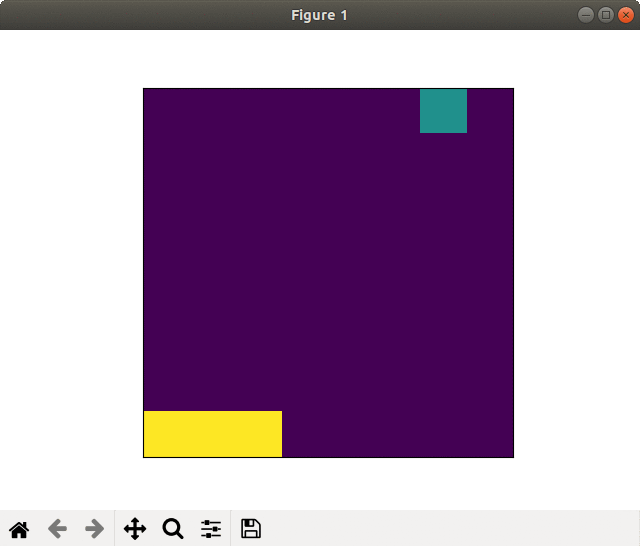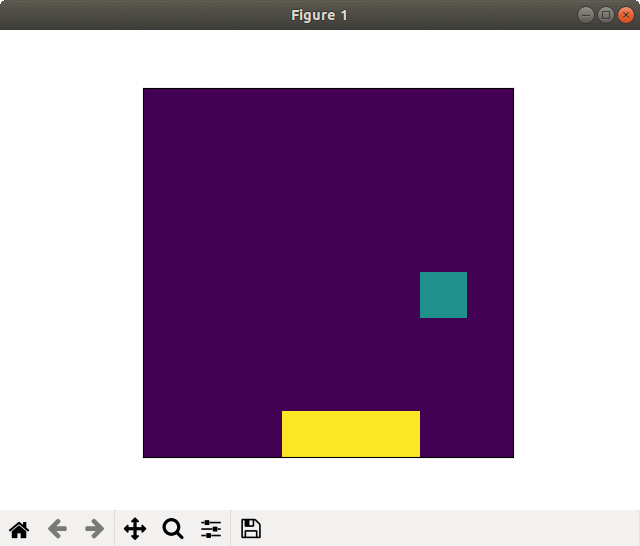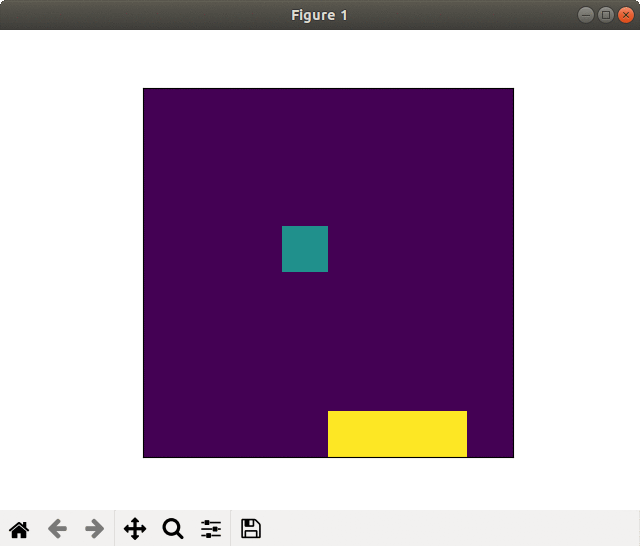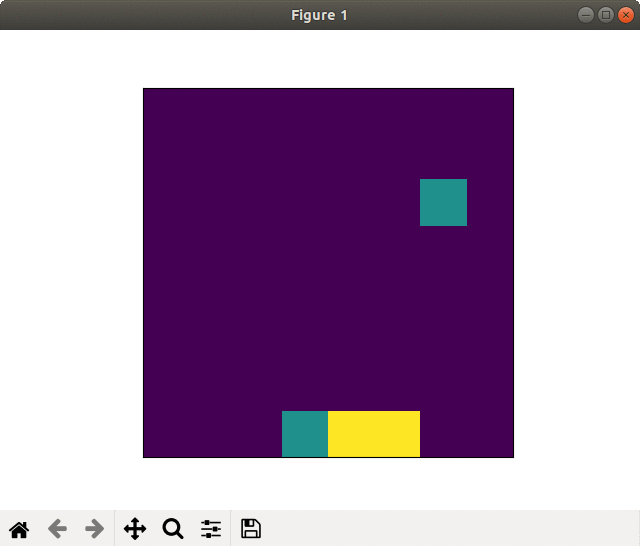
Race is competed on the image with 32 × 8.
It starts from the upper edge.
If an agent reaches the bottom edge before rivals, it is win.
The bar shown at the right side of the image shows the remaining energy.
Field. Although it looks like color image with "jet" color map, it's single a scale between 0.0 to 1.0.
(2) Player
The player learns goal sprint.
Player
actions of 4 patterns
1 sprint consumes 1 energy
If remaining energy is 0, sprint(0) is the same to go straight(2)
Initial energy is 5
Big movement with 2 pixels to the lateral directions are set for generating the tactics of chasing the back of rivals.
(3) Competitor
The competitor moves randomly.
Competitor
actions of 4 patterns(randomly selected)
1 sprint consumes the 1 energy
If remaining energy is 0, sprint(0) is the same to go straight(2)
Initial energy is 6
Note: I considered that strong competitor encouraged the accomplishment of clever strategy, so I tried high initial energy like 10.
But I realized that too strong competitor prevented learning because the player seldom won.
Thus I used 6 as initial energy of the competitor, that is close to the one of player.
As I explained below, the slipstream does not work on the competitor.
That means the energy of competitor never recovers.
So I guess the potential strength of the two is very close.
(5) Slipstream
I imitated slipstream using simple rules because calculating fluid mechanics is very very hard.
Imitated slipstream
If the player is 1 pixel behind of the competitor, the player's energy recover 2
If the player is 2 pixel behind of the competitor, the player's energy recover 1
Slipstream works only on the player.
(6) Expression of race progress
This was the hardest point in this article.
Many of image processing using neural network, including deep learning, is a reaction from a image.
It is not good at learning long-term tactics like saving energy at the beginning of the race for preparing to goal sprints.
Recurrent neural network(RNN) is a popular way for make neural network learn time series forecasting.
For example, long short term memory(LSTM) is often used in natural language processing.
I heard some studies tried the recurrent neural network in image processing.
This time I selected the simple way: arranging the images with time series at the channel direction.
Reinforcement learning is a very new field for me, so I preferred to a classical way.
Expression of race progress. Images with time series were arranged at the channel direction.
Initialize 32 images(channel) as zero
In every step, the new channel is updated. So the past remains in old channels.
When the race is finished, images are fixed and inputted to neural network. Thus, several channels are remains as 0.
(7) Reward
Bike race is all or nothing as riders often say "second places is the same to 10th."
So I set the reward in a simple way.
Win: 1.0
Lose: -1.0
There was s problem.
In this way, we can give reward only when the result is decided.
To learn race progress, we need to give reward to the past.
It is important to let the neural network know the actions that are highly possible to grab wins in the end.
Thus, I assigned reward on the past in the linear way relative to the finish step.
Because the rewards for past are not decided until the race is finished, I used experiences only at the loop with race finish.
train.py
if terminal:
# experience replay
agent.experience_replay()
2. Result
Because of random values included in the program, the learning results were not always the same.
There were both the case with successful and failed learning.
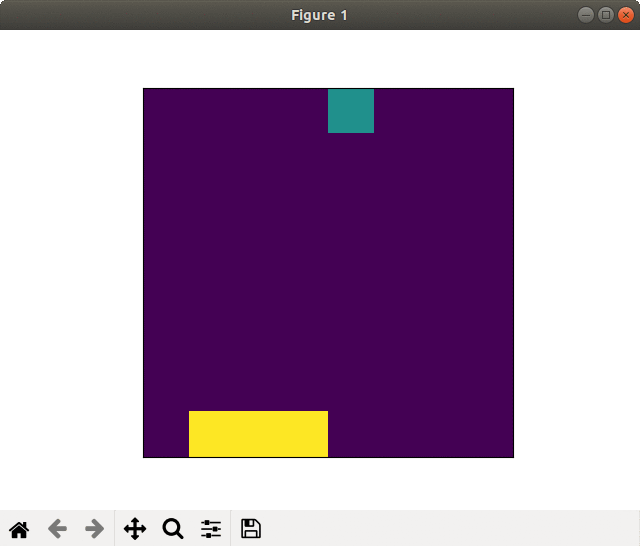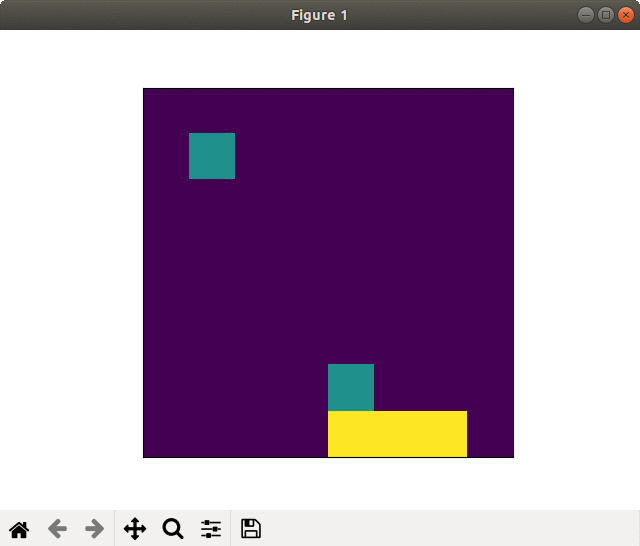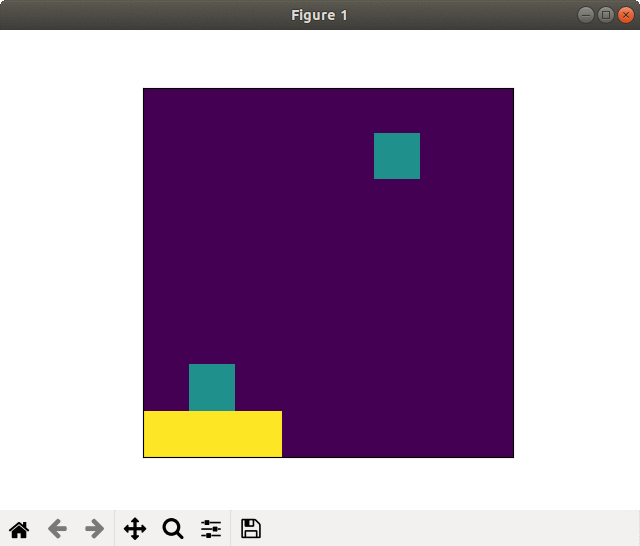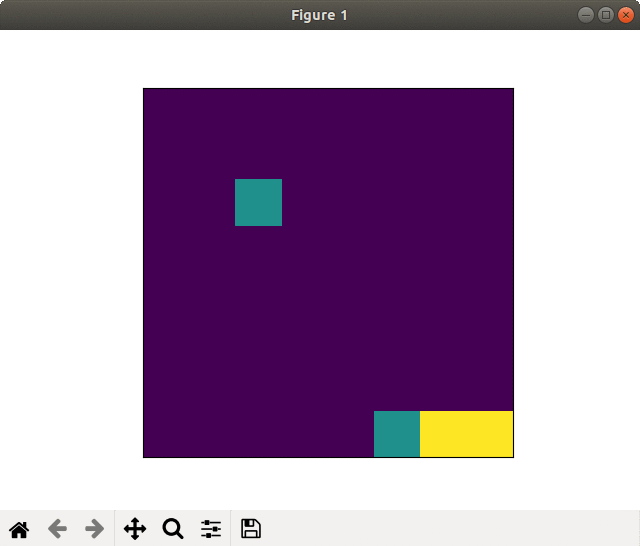
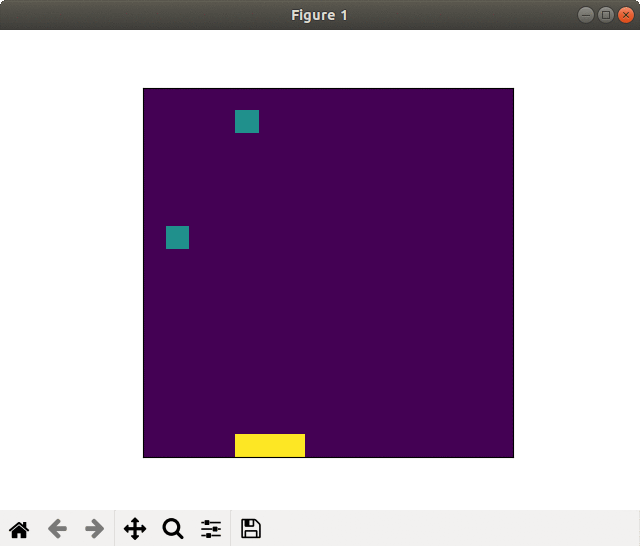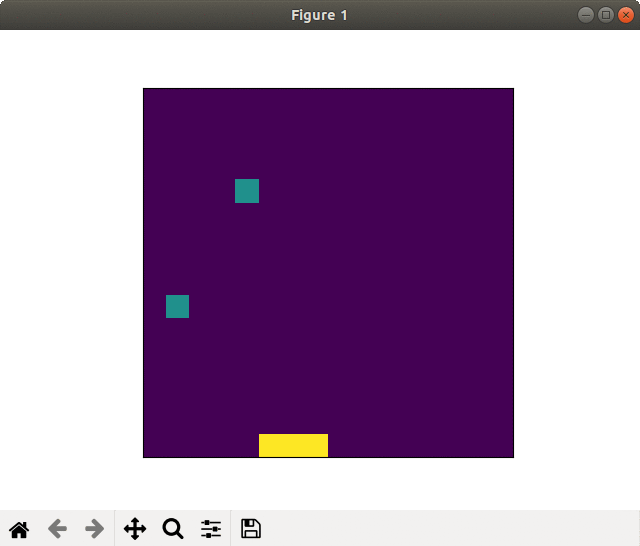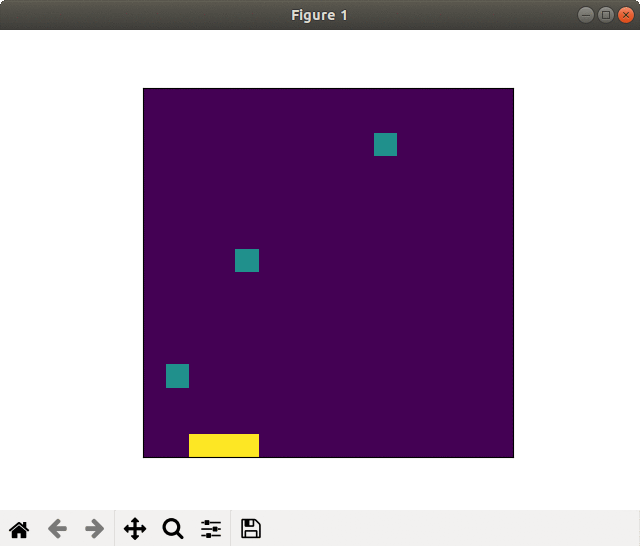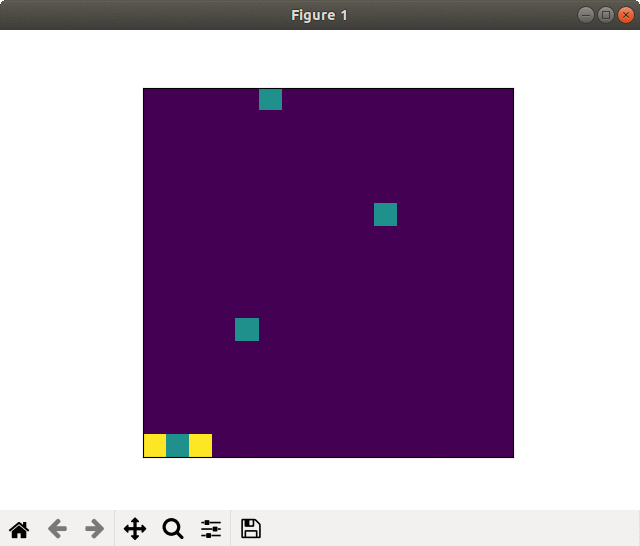
Case of failed learning(20000 epoch). Self-destruction with kamikaze-attack
Successful learning(20000 epoch). Goal sprinting near the finish
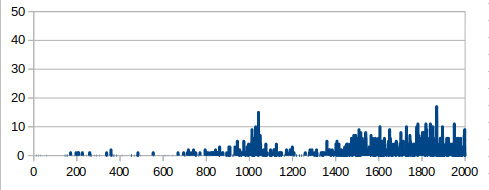
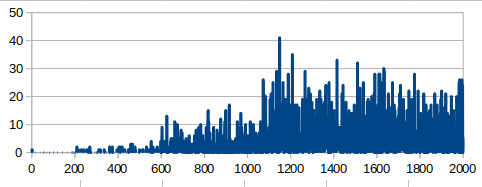
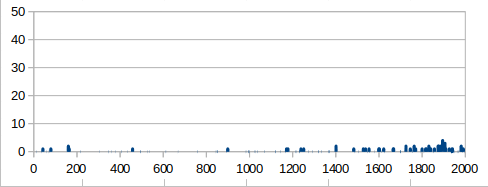
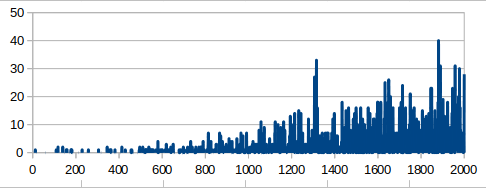
Winning rate during learning. You can see that successful learning (=orange, goal sprint) acquired the superior tactics with high winning rate
I compared the tactics and winning rate during learning of the two cases.
In the case of failed learning, the player took sprint from the begging and run out energies, so to called "kamikaze-attack."
The winning rate (blue in the graph) rapidly rose soon after the learning start but stagnated.
On the other side, in the case of successful learning the player saved (recovered) the energies using slipstream and goal sprinted.
Its winning rate(orange in the graph) continued to rise slowly and accomplished the high value in the end.
The result shows that you need to learn from defeats to be strong.
It is possible that a rider who learn a lot from defeats becomes stronger than a rider who wins a lot soon after the start of carrier.
I have no confidence that the player used lateral movement to catch the back of the competitor.
The player tended to dash when the competitor occasionally came in the front, and surpassed before the finish.
I think It is a little different phenomena of the real.
3. Afterward
It was a interesting experiment.
I want to make the neural network generate the new tactics that has not yet been used in the real.
時系列や文脈をニューラルネットワークに学習させる方法の代表例が,再帰型ニューラルネットワーク(RNN)です.
代表例のLSTM(Long Short Term Memory)が,近年の自然言語処理でよく使われています.
画像処理に再帰型を導入した実例もある様ですが,強化学習という慣れない分野で策を凝らすのは疲れると思いました.
このため,今回はシンプルにチャンネル方向に画像を並べることにしました.
レース展開の表現.時系列毎の画像をチャンネル方向に配置
32枚(チャンネル)の画像を0初期化する
1ステップ毎にチャンネルをずらしながら,画像を更新する
勝敗が決まった時点で画像を確定し,ネットワークに入力する(数チャンネルは初期(0)画像のまま)
(7) 報酬
自転車レースは「2位はビリと同じ」と言われる位にall or nothingの世界です.
ですので,報酬はシンプルに設定しました.