こんにちは,changです. 今回は強化学習に自動車ロードレース(っぽいこと)をさせてみます.

0. 自転車ロードレース
日本では馴染みが薄い自転車ロードレースですが,ヨーロッパではサッカーやF1に次ぐ程の人気スポーツです. およそ10年前,僕はその魅力に取りつかれました.
自転車レースの魅力についてはここでは語り切れません. でも一つだけ,今回の記事を書くに当たって説明する必要があります. スリップストリームです.
簡単に言うと「他人の背後を走ると楽に走れる」現象です. ドラフティングと呼んだりもします. グリスアップされたロードバイクでは,進行に際して生じる抵抗の大部分が空気抵抗になります. 時速40 kmやそれを超える速度で走っていると,自分の身体が風を押し広げながら進んでいるのを感じることが出来ます. 他人の後ろを走ると,風の抵抗をその他人が代わりに受けてくれる為,楽に走れるのです.
例えばこの記事*1で紹介されている海外の研究論文によると,2人で走って後ろに付いた場合には35.6%,3人で走って後ろに付いた場合には47.8%のパワー削減になるそうです. チーム練習やレースにおいて,実際にその位の効果を感じます. 流体力学のシミュレーションをしてくれている方もいますね*2.
スリップストリームが在ることで,自転車レースは頭脳戦・心理戦になります. 他人の後ろに隠れて体力を温存することが,勝機に繋がるからです. これ*3をみると良くわかりますが,最後に処理をつかむ選手は大抵,ゴール直前まで他の選手の後ろに潜んでいて,最後の最後に力を爆発させる(=ゴールスプリント)のです.
今回はこのゴールスプリントを強化学習にやらせて見ようと思います.
1. プログラム
前回書いたサンプル*4を,自転車ロードレースに合わせて書き直して行きます.
(1) フィールド
32 × 8画像の上から下方向にレースをさせます. 速く最下行に到達した方が勝ちです. 右端にあるバーは,後述するエネルギーの残量を表しています.

(2) プレイヤー
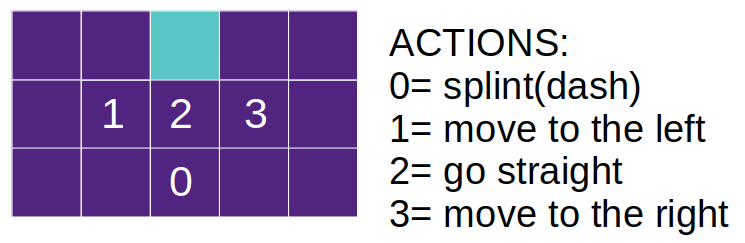
こいつにゴールスプリントをさせます.

- アクションは4パターン
- 1回のスプリントで,エネルギー1を消費する
- エネルギーが0になると,スプリント(0)は前進(2)と同じ動きになる
- 初期エネルギーは5
- コンペティターの背後に入る動きを発生させる為,横方向の動きを大きくしている
(3) コンペティター
こいつにランダムに動いてもらい,競争相手になってもらいます.
- アクションは4パターン(ランダム)
- 1回のスプリントで,エネルギー1を消費する
- エネルギーが0になると,スプリント(0)は前進(2)と同じ動きになる
- 初期エネルギーは6
Note: コンペティターが強い(初期エネルギーが大きい)方がより狡猾に(?)戦略を学習すると思ったのですが,コンペティターが強すぎると勝てるケースが少なすぎて学習が進みませんでした. このため,今回はコンペティターの初期エネルギーを(プレイヤーに対して1多いだけの)6にしました. 後述するようにコンペティターにはスリップストリームが効かない(エネルギーが回復しない)ので,プレイヤーとコンペティターの戦力は切迫していたと思います.
(5) スリップストリーム
流体力学を計算するのは大変なので,簡単なルールで擬似することにしました.

(6) レース展開の表現
今回,一番苦労したところです. ディープ・ラーニングもそうですが,基本的には画像に対しての一問一答の構造です. レース前半にエネルギーを温存し,後半にゴールスプリントをしかえるといった「展開」を学習することには不向きです.
時系列や文脈をニューラルネットワークに学習させる方法の代表例が,再帰型ニューラルネットワーク(RNN)です. 代表例のLSTM(Long Short Term Memory)が,近年の自然言語処理でよく使われています. 画像処理に再帰型を導入した実例もある様ですが,強化学習という慣れない分野で策を凝らすのは疲れると思いました. このため,今回はシンプルにチャンネル方向に画像を並べることにしました.

- 32枚(チャンネル)の画像を0初期化する
- 1ステップ毎にチャンネルをずらしながら,画像を更新する
- 勝敗が決まった時点で画像を確定し,ネットワークに入力する(数チャンネルは初期(0)画像のまま)
(7) 報酬
自転車レースは「2位はビリと同じ」と言われる位にall or nothingの世界です. ですので,報酬はシンプルに設定しました.
- 勝利: 1.0
- 負け: -1.0
単純にこうしてしまうと,勝敗が決した時点での画像にしか報酬を与えることが出来ません. レース展開を学習させるためには,レースが決着する前の画像にも報酬を与え,勝利をつかむ可能性の高いアクションを学ばせる必要があります. このため,勝利が決した時点から遡って線形に,過去の画像に報酬を割り振ることにしました.
dqn_agent.py
def experience_replay(self):
...(中略)...
size = len(self.D)
tmp_state, tmp_action, tmp_reward, tmp_state_1, tmp_terminal = self.D[size - 1]
for j in range(minibatch_size): # minibatch_indexes:
...(中略)...
reward_minibatch.append(tmp_reward * j/(minibatch_size - 1))
...(中略)...
このやり方だと,勝敗が決まる前の画像であっても,勝敗が付くまで報酬が確定しません. このため,勝敗が決したループのみで経験を積ませることにしました.
train.py
if terminal:
# experience replay
agent.experience_replay()
2. 結果
乱数を使っている為,同じプログラムで計算を回しても学習が進む場合と進まない場合がありました.



学習中の勝率の推移を比較しました. 学習が進まなかった先行逃げ切り型(青)では,学習開始直後から一気に勝率が上がり,その後横ばいになりました. 一方,学習が進んだゴールスプリント型(橙)では,学習開始直後から継続的に学習が進んだ結果,高い勝率を獲得しました. このことは,強くなる為には「失敗から学ぶ」必要があることを示しているでしょう. キャリアの序盤に大量の勝利を積んで戦略を学ぶのを怠った選手よりも,多くの敗北から経験を積んだ選手のほうが最終的には強くなるのかも知れないですね.
学習が進んだケースを繰り返し見てみましたが,横の動きでコンペティターの背後に付く動きをしたかというと少し怪しいです. どちらかと言うと,コンペティター側が偶然自分の前に入って来た時に加速してエネルギー回復をさせ,ゴール手前で一気に抜き去っていました. 現実とは少し異なる動きなので,改良しようと思います.
3. むすび
面白い実験ができました. 現実では起きていない戦略を,強化学習に創造させる事が出来たら最高ですね(^^). 試してみたい事が色々あるので,順次,発表して行くつもりです.
今回書いたソースはここ*5です.