こんにちは.changです.
今回は強化学習をやってみます. ディープ・ラーニングにも少し飽きてきたので...(笑).
作ったのはよくあるインベーダー的なやつです. やってみると意外と大変でした(汗). kerasの環境が整っていなくて,tensorflow単独に先祖返りする感じです.
0. 今回の目的
冒頭にも触れたように,ディープ・ラーニングにも大分飽きて底が見えてきました.
原理的な探求には区切りをつけ,実用性を重視したアプリケーション開発に移行するタイミングだと思っています.
本来はここからが仕事(=営利活動)なのですが,こればかりをやっていると直ぐに時代遅れになってしまいます.
次の素材に手を出し始めようと考えました.
で,AIつながりで浅はかですが,強化学習をやってみます.
情報の少ないアルゴリズムを動かすときに大切なのが,ベースとなり,かつ整然と書かれたサンプルを持つことだと考えています. ディープ・ラーニングではmnist*1とU-Net*2がそれでした. 僕の書くソースのほとんどはこの2つのソースの派生になっています. 単に裾野が狭いとも言える...(汗).
ベースが出来てしまうと,そこからの派生や応用は案外簡単にできるものです. また,立ち返る原点が定まっていれば,迷っても初めからやり直しできます. 「やり直し」を「出戻り」と読んで避難するヒトもいますが,,,同じ条件でもう一度やり直せば,必ず一度目よりも速く,賢くゴールに辿り着く筈です.
今回の目的は,このベースを強化学習について構築することです.
1. 強化学習
あちこちで紹介されているので,詳しい説明は省きます. というより,僕自身が勉強不足で詳しい説明が出来ません(笑).
イメージだけで話しますが,強化学習は所謂「教師無し学習」です. Alpha GOがプロ棋士を負かしたという話はあまりにも有名ですが,Alpha GOの凄いところはヒトの対戦を真似るのではなく,自身で対局を繰り返して勝手に強くなることです.
少し前に,藤井聡太君が50万円の自作PCで将棋ソフトを使っているという記事が話題になりました. 将棋ソフトについて,彼が「予想のしない手を打ってくる」と発言していた記憶があります(羽生さんだったかも). これは,ヒト(=教師)の模倣ではない強化学習ならでは特徴だと言えます.
ヒトが発想出来なかったアイデアを創発することが,僕が強化学習に期待することです.
2. keras
一年位前からkerasを使い始めました. 「モデルを書くのが楽」という声をよく聞きますが,最大の恩恵はデバッグのしやすさです. tensorflow単独でのプログラミングはPlaceholderの中身を追えない為,非常に厄介です. kerasを使うと,C言語的というか,ひとつながりのデータの流の中で自分の書いたソースを追いかけることが出来ます. 強化学習でも,このメリットを生かしたいと考えました.
3. プログラム
(1) 参考にしたソース
いくつかの簡易版がシンプルに動作しますが,tensorflow単独で書かれていました. この方*3はkerasを使われていますが,ご本人もおっしゃっているようにkerasを使うことによって逆にソースが煩雑になっています. この方*4のソースは,モデルの記述にのみkerasを使っています. また,簡易版ではしばしば省略されているtarget network等も丁寧に書かれていて,発展性が高いと思いました. ただ,表示部が無い(公開されていない?)のです. 理想を満たすサンプルはなかなか見つかりません...(>.<). 結局,これらのソースを自分で統合することにしました.
(2) ルール
参考にしたソースそのままです.
- 爆弾(?)をキャッチしたら報酬1
- 爆弾を落としたら報酬-1 & ゲーム終了
- 右に動く,左に動く,動かないの3パターンの中からアクションを選択
- フィールドは8 × 8または16 × 16から選んで設定
(3) ネットワーク
シンプルな全結合版と,少し複雑な畳み込み版の2パターンを書きました.
シンプルな全結合版
def build_model(input_shape, nb_output):
model = Sequential()
inputs = tf.placeholder(dtype=tf.float32, shape=[None,input_shape[0]*input_shape[1]], name="input")
model.add(InputLayer(input_shape=(input_shape[0]*input_shape[1],)))
model.add(Dense(64, activation="relu"))
model.add(Dense(nb_output))
outputs = model(inputs)
return inputs, outputs, model
少し複雑な畳み込み版
def build_model_cnn(input_shape, nb_output):
model = Sequential()
inputs = tf.placeholder(dtype=tf.float32, shape=[None,input_shape[0]*input_shape[1]], name="input")
model.add(InputLayer(input_shape=(input_shape[0], input_shape[1], 1)))
model.add(Convolution2D(16, 4, 4, border_mode='same', activation='relu', subsample=(2, 2)))
model.add(Convolution2D(32, 2, 2, border_mode='same', activation='relu', subsample=(1, 1)))
model.add(Convolution2D(32, 2, 2, border_mode='same', activation='relu', subsample=(1, 1)))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dense(nb_output, activation='linear'))
outputs = model(tf.reshape(inputs, shape=[-1, input_shape[0], input_shape[1], 1]))
return inputs, outputs, model
(4) 最適化関数
最適化には,tensorflow標準のRMSPropを使いました. ここ*5で紹介されているのように,論文発表者の改変版を使のがベターの様です.
optimizer = tf.train.RMSPropOptimizer(learning_rate=self.learning_rate)
4. 学習結果
(1) 8×8フィールド
2000スペック&全結合版でもそこそこの学習効果がありました.
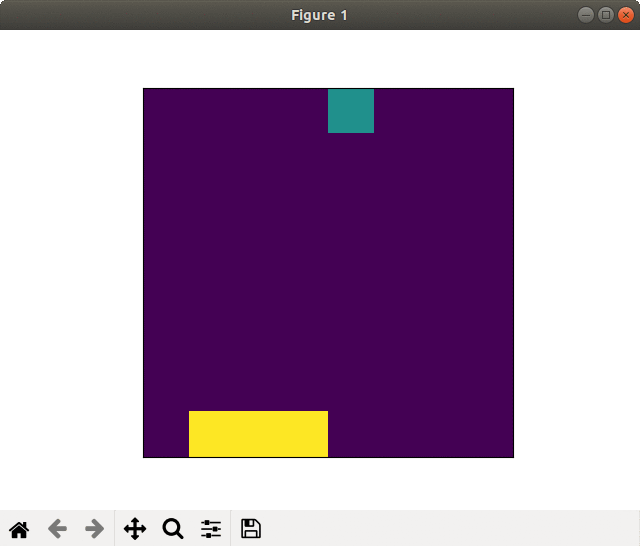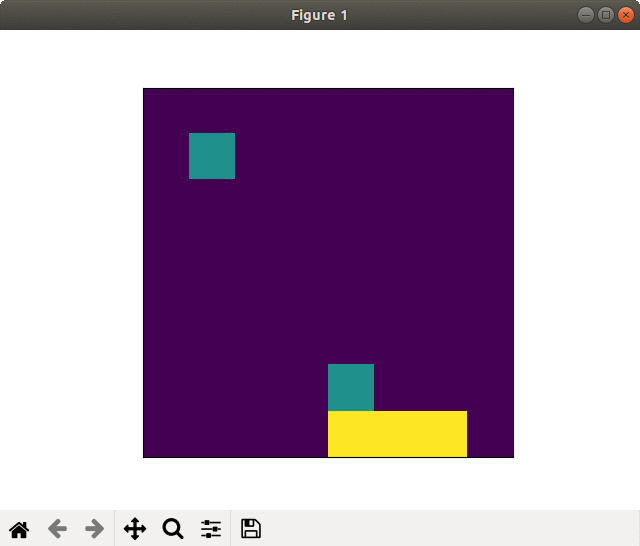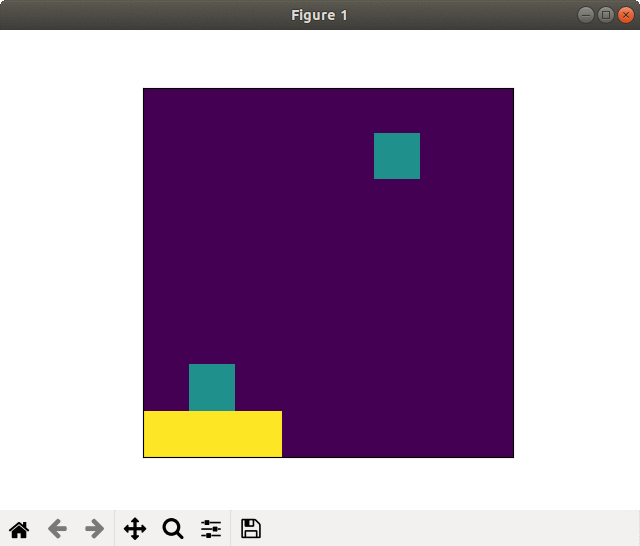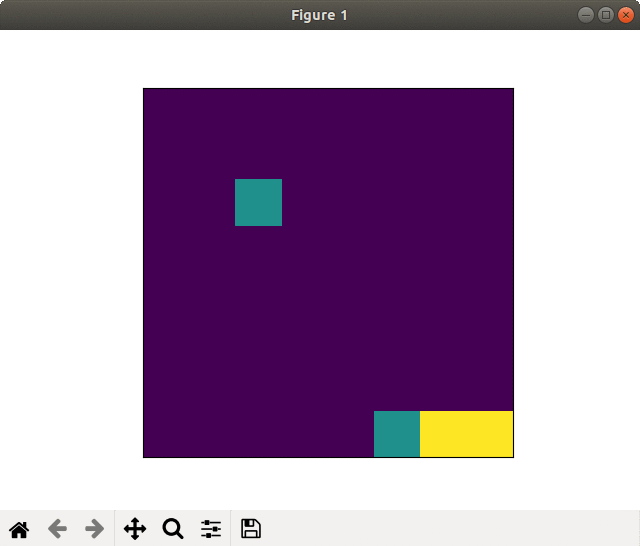
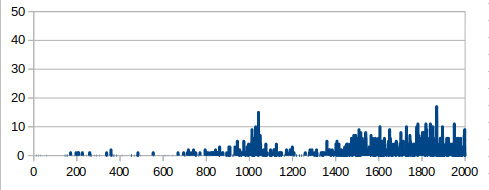
ネットワークを畳み込み版に変えると,更に良くなります.
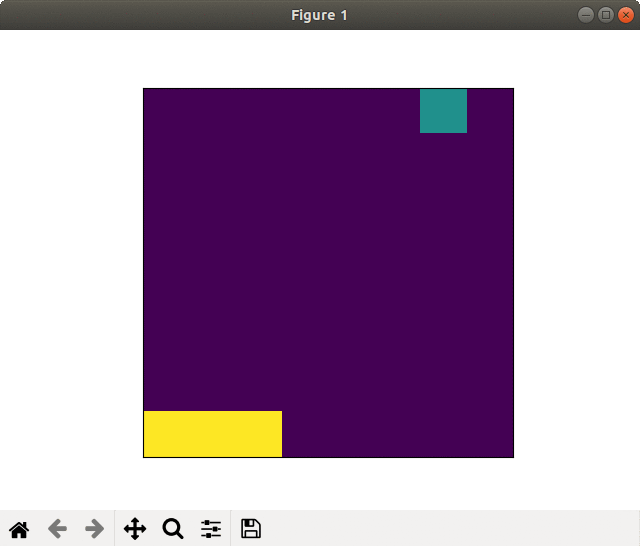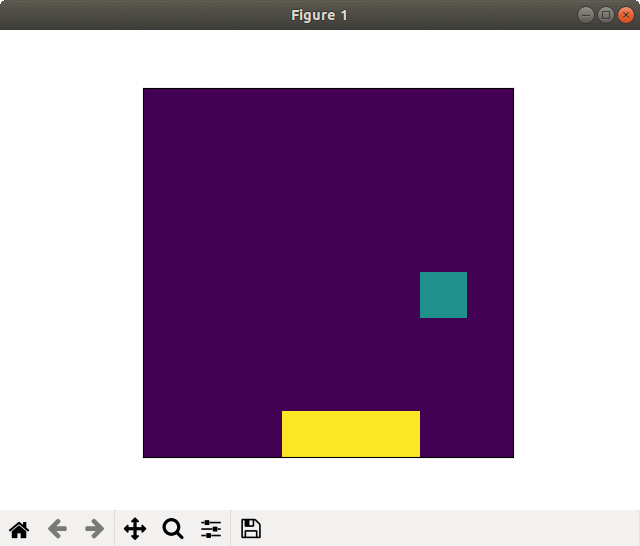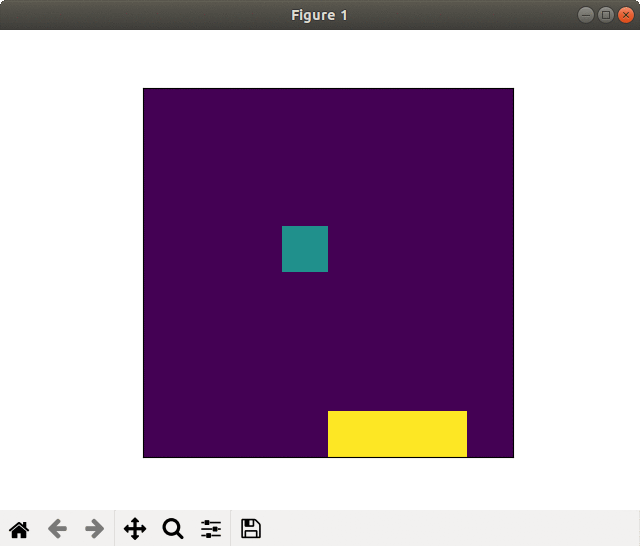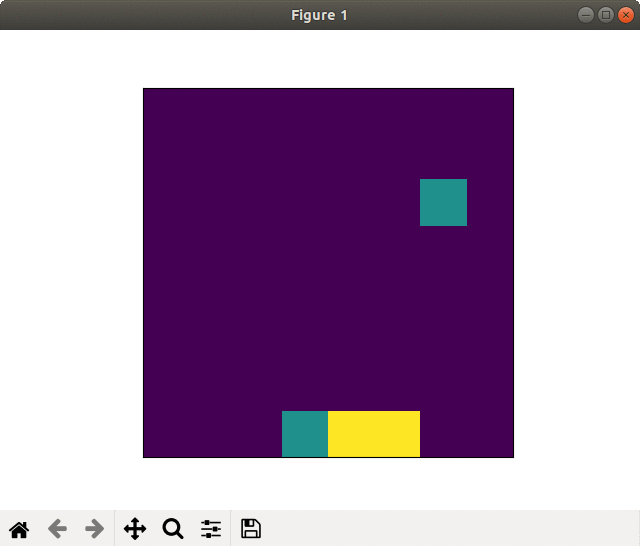
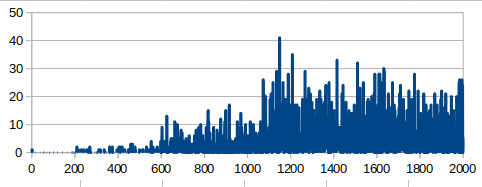
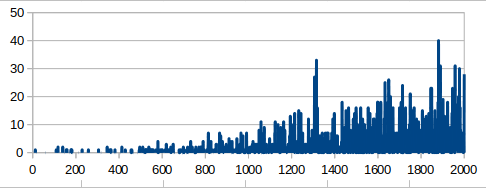
(2) 16×16フィールド
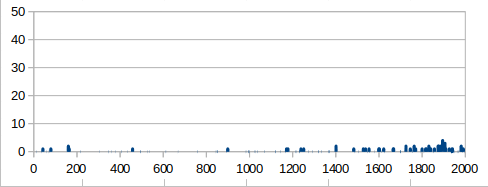
2000スペック & 全結合版では,爆弾をほとんどキャッチしませんでした.
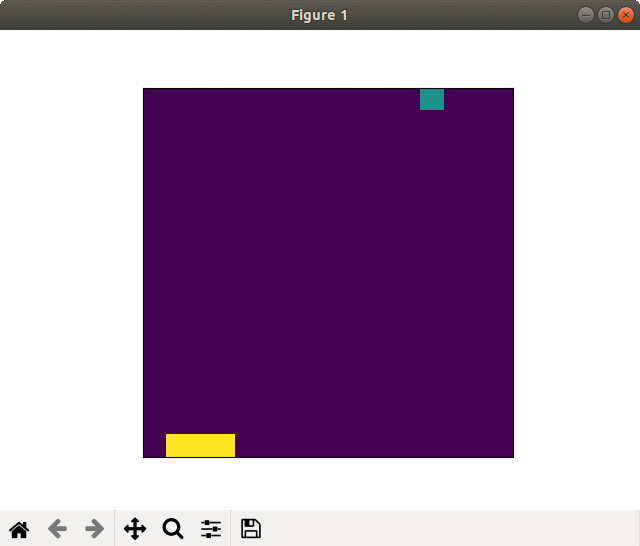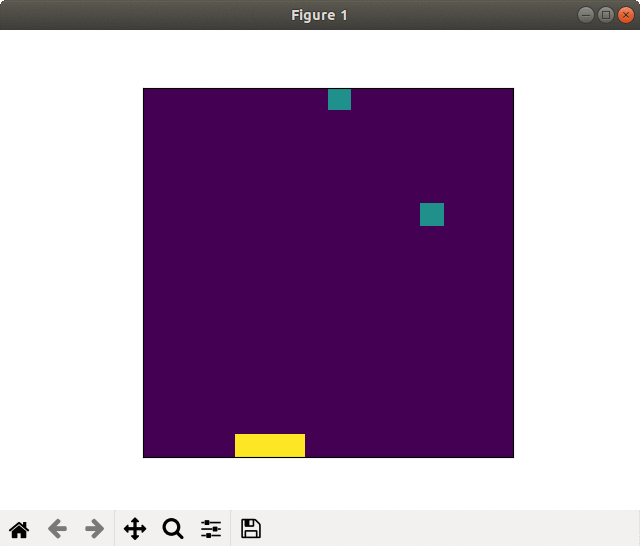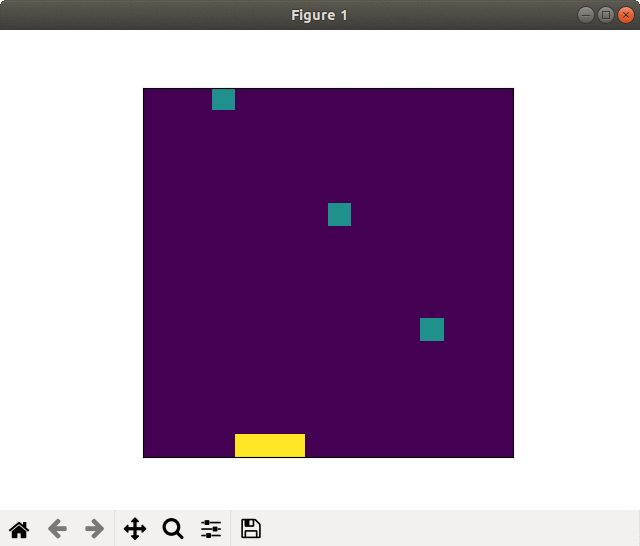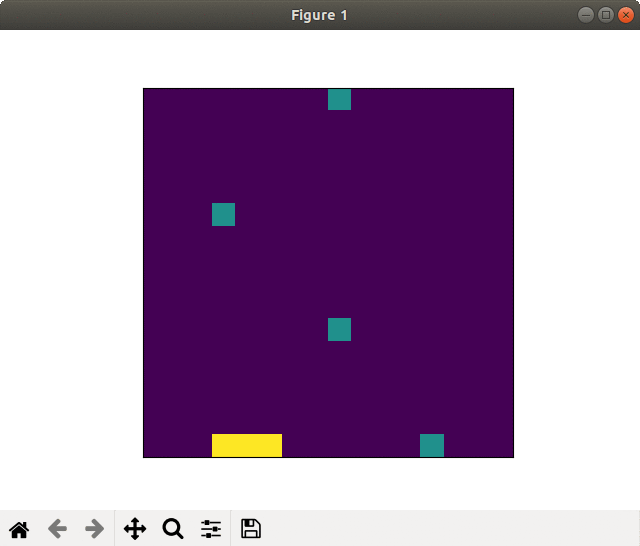
2000スペック & 畳み込み版でそれなりな動きになりました. 未だ未だ,工夫が必要な感じがしますね.
5. 結び
新しい素材に触れるのは楽しいですね.
今回残念だったのが,kerasのメリットをほとんど活かせ無かった事です. モデルの記述にはkerasを使いましたが,ネットワークへの入力にはPlaceholderを使いました(使わざるを得ませんでした). これでは,tensorflow単独でのプログラミングとほぼ変わりません. 新しいkerasやtensorflow ver. 2では改善されているのかも...?
今回のソースが,強化学習を作っていく上でのベースとして機能するか未だ判りませんが,取り敢えずの起点は作れたと思います. 自分なりの工夫を加えて遊んでみるつもりです.
今回書いたソースはここ*6です.
*1:https://changlikesdesktop.hatenablog.com/entry/2020/04/18/175527
*2:https://changlikesdesktop.hatenablog.com/entry/2020/05/25/090818
*3:https://qiita.com/yukiB/items/0a3faa759ca5561e12f8
*4:https://www.tcom242242.net/entry/ai-2/%e5%bc%b7%e5%8c%96%e5%ad%a6%e7%bf%92/%e6%b7%b1%e5%b1%a4%e5%bc%b7%e5%8c%96%e5%ad%a6%e7%bf%92/%e3%80%90%e6%b7%b1%e5%b1%a4%e5%bc%b7%e5%8c%96%e5%ad%a6%e7%bf%92%e3%80%91deep_q_network_%e3%82%92tensorflow%e3%81%a7%e5%ae%9f%e8%a3%85/