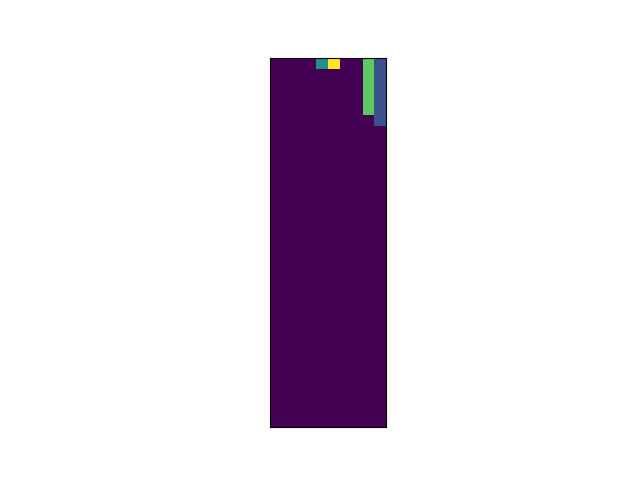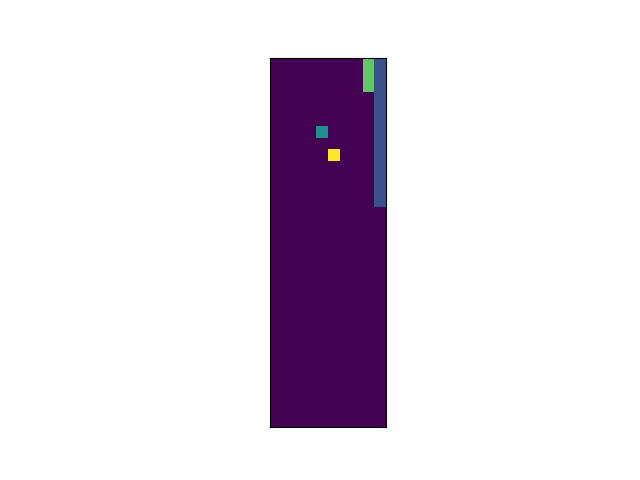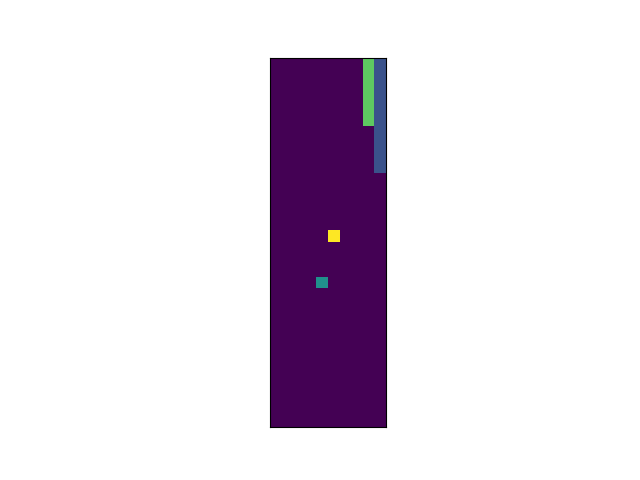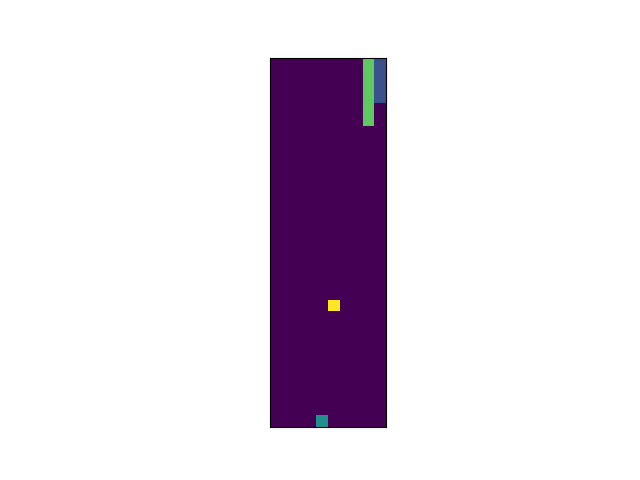This article is a translation of Japanese ver.
Original ver. is here*1.
Hi, this is chang.
In this article, 4 artificial intelligent racers (M*cEwan, P*tacchi, C*vendish, C*nchellara) competed each other and learned their tactics.
0. Bicycle road race
Bicycle road race is spectacle.
It has some special factors like slipstream.
They make race complex and full of humanity.
To check the background knowledge for seeing bike race, please see the published articles*2*3.
Today I used 4 riders as models.
I guess if you know them, you can enjoy the article much more.
I picked YouTube videos that featured them*4*5*6*7.
I hope the videos help you.
Sorry but I could not find the information source that compared the characteristics of the four.
1. Program
(1) Field
Race is competed on the image of 32 × 12.
It starts from the upper edge.
If an agent reaches the bottom edge before rivals, it wins.
The bar at the right side of the image shows the remaining energy of riders.
Today I increased the width from 8 to 12 because of increased players.
Field
(2) Player
Today I did not distinguish between players and competitors.
Instead, 4 players equally competed against each other.
M*cEwan
M*cEwan
actions of 5 patterns
1 and 2 dash consumes 1 and 2 energy, respectively
Super sprint with energy shortage goes only remaining energy value
If remaining energy is 0, sprint(0) and super sprint(4) is the same to go straight(2)
Initial energy is 5
Big lateral motion with 2 pixels are set for catching the wheels of rivals.
M*cEwan type: weak in long sprint(=small initial energy) but good at quick action(=big lateral move)
P*tacchi
P*tacchi
actions of 5 patterns
1 and 2 dash consumes 1 and 2 energy, respectively
Super sprint with energy shortage goes only remaining energy value
If remaining energy is 0, sprint(0) and super sprint(4) is the same to go straight(2)
Initial energy is 6
P*tacchi type: Large body(=small lateral move) and good at long sprint(=large initial energy)
C*vendish
C*vendish
actions of 5 patterns
1 and 3 dash consumes 1 and 3 energy, respectively
Super sprint with energy shortage goes only remaining energy value
If remaining energy is 0, sprint(0) and super sprint(4) is the same to go straight(2)
Initial energy is 5
C*vendish type: Superior in explorive power(=super sprint of 3 pixels)
C*nchellara
C*nchellara
actions of 5 patterns
1 dash consumes 1 energy
If remaining energy is 0, sprint(0 or 4) is the same to go straight(2)
Initial energy is 10
C\nchellara type: Poor sprint(=no super sprint) but special in endurance(=large initial energy)
(3) Slipstream
I imitated slipstream using simple rules.
Players can recover their energy by taking back of rivals.
Imitated slipstream
If a player is 1 pixel behind of others, the player's energy recovers 2
If a player is 2 pixel behind of others, the player's energy recovers 1
(4) Reward
Win: 1.0
Lose: -1.0
I used the all or nothing concept like the previous. If drawn, reward is the same to lose(=-1.0).
Note: Please also check published articles to check the detail of the program.
2. Result
There were much more variation in results because of increased players.
Although I wanted to test cases as many as possible, it took time.
So I stopped calculation at 10 cases.
(1) Winning percentage
Case
M*cEwan
P*tacchi
C*vendish
C*ncellara
Draw
0
0.073
0.157
0.503
0.000
0.267
1
0.497
0.107
0.177
0.000
0.219
2
0.037
0.010
0.057
0.010
0.886
3
0.390
0.013
0.123
0.003
0.597
4
0.133
0.320
0.130
0.000
0.417
5
0.033
0.017
0.087
0.003
0.860
6
0.043
0.817
0.063
0.000
0.077
7
0.650
0.120
0.040
0.020
0.170
8
0.023
0.330
0.247
0.200
0.200
9
0.220
0.250
0.247
0.033
0.250
Sum
0.210
0.210
0.170
0.030
0.390
Table above shows the winning percentage of 300 races using neural networks after training.
It showed that:
M*cEwan and P*tacchi dominated races
C*vendish was ranked in third
C*anchellara was an only loser
Note: I would like to say that I do not have a hate on C*nchellara
I made gif animations of the winning pattern of each racer.
The gif animations of all the cases are here*8.
M*cEwan(red) sprinted from behind rivals. Extract of Case 1P*tacchi(orange) sprinted from behind rivals. Extract from Case 6C*vendish(yellow) super-sprinted from behind rivals. Extract of Case 9C*anchellara(sky-blue) overpowered. No training. He was the strongest in random motions, at the early stage of learning
Case
M*cEwan
P*taccchi
C*vendish
C*nchellara
0
/
/
break
/
1
splint
/
/
/
2
break
/
break
/
3
break
/
break
/
4
break
sprint
break
/
5
break
/
break
/
6
/
sprint
/
/
7
break
/
/
/
8
break
sprint
sprint
/
9
break
sprint
sprint
/
The table above shows the tactics of each case.
I felt that the tactics were naive compared to previous tests with two players*9*10.
Although they learned goal sprints, they often went too fast and lose legs before finish.
In addition, all the four did not battle for races.
In many cases, only two sprinted and the rest looked on from behind.
3. Consideration
(1) Training epochs
One of the causes for poor tactics was just a lack of training epochs.
Winning percentage during learning of Case 0
Above is the transition of winning percentage during training of case 0.
The wins of P*tacchis and C*vendish increased at about 25000 epoch and kept rising till the end(50000 epoch).
It is possible that more skilled sprint was acquired with additional training.
Although I increased epoch from 20000 to 50000 today, it did not seem to be enough.
I think this is because the variation in the field were dramatically increased with increased players.
(2) Negative brain
Not all the four players were aggressive in many cases.
I'm trying to understand this phenomena.
Let's see again the transition of winning percentage of case 0.
When M*cEwan and C*vendish improved at 25000 epochs, the wins of C*nchellara decreased.
In this program, only the four players exist.
So if one wins, other one necessarily loses.
It was difficult to train all the players at the same time.
In many cases, C*nchellara dominated races at the early stage of training, 25000 epoch or less.
This is because his high initial energy is quite advantageous in random motions.
But shown in the gif aminations above, C*nchellara tended to lose with his energy remained.
If he used his energy, he may win.
But he did not do that.
I think his neural network, that gained reward with random motions in the early stage of training, denied when rivals became strong.
The winning pattern of the past was destroyed. In the result, the network fell into the situation of negative brain.
The riders in real sometimes lose their rhythm after a series of loses.
I guess it is the similar situation.
By the way, we today have 4 players.
Each player learned more loses than wins (lose 3/4 and won 1/4) and was easy to be in negative brain.
So I tried to use only the experience of wins like the code above.
Sadly, it did not work well.
In addition, to forget the past loses, I set the replay memory size as 10 races.
It also did not work well.
I guess that the experience of loses gradually increased and dominated the memory in the end.
In real, riders do not always run the same races.
In many cases, riders trained in their home countries and face in big races.
It is possible that training in different races has the efficiency to avoid the negative brain.
Like Fabian Canchellara of 2010 and Philippe Girbert in 2011, a rider sometimes dominates the big races.
I think it is possible that many rivals were in the state of negative brain.
In trial, I gathered the networks that riders were up-beated (M*cEwan: Case 1, P*tacchi: Case 6, C*vendish: Case 0, C*ncheralla: random) and made them race.
So aggressive!!!
Never tired of watching close battles.
Race among positive brains. Example 1(6 races). Red=M*cEwan, Orange=P*tacchi, Yellow=C*vendish, Sky blue=C*nchellaraRace among positive brains. Example 2(6 races). Red=M*cEwan, Orange=P*tacchi, Yellow=C*vendish, Sky blue=C*nchellara
(3) C*nchellara was a trainig rival
I am afraid of bashing from Canchellara's funs...
I say this again.
I do not have a hate on him.
I'm writing objective analysis about the phenomena.
Fact, C*nchellra was an only loser today, but he played an important role in competition.
Let's see the learning transition of case 0 again.
P*tacchi and C*vendish were likely to become strong through the fight with C*nchellara.
Win rate during learning of Case 2
It is obvious in case 2 shown above.
Case 2 had many drawn game and tended to be boring.
In the winning transition of case 2, C*nchellara's dominance at the early stage of training did not happen.
No players rose their winning rate.
In the result, so many drawn games made all the players be defensive.
It shows that all the players fall into numb without rivals who take a risk.
I can say that elegant tactics generate from the battle against the strong, physically superior(=great initial energy in this game) rivals.
4. Afterward
It may be possible to mention not only the tactical aspects but also the training plans based on the brain science.
By the way, it was quite hard to edit the article because the learning took a lot of time.
My computer worked with illumination at night and prevented my sleep.
And to he honest, translation is also bothersome, ha ha ha...
I have to pay with attention on my health.
Next, I will try the race with team.
I wonder why C*vendish was not well today.
His characteristics must be strong if he saves power till the end of races.
The race among personals, that requires riders to chase breakes by themselves, was not suit for him.
I do want to observe the super sprint of C*vendish from the team train.
for j in range(minibatch_size): # minibatch_indexes:
game_length = len(self.D[j][0])
reward_j = self.D[j][1]
for i in range(game_length):
...
reward_minibatch.append(reward_j * i/(game_length - 1))
1ゲーム毎に遡って,報酬を与えます.
(6) 報酬
今回苦労したところです.
前回まではAll or Nothingの思想の下で実践形式の報酬を与えていました.
色々と調査したところ,All or Nothing報酬では,チームトレインを組む動きが全く発生しませんでした.
勝利をつかむパターンが多岐に及び,トレインに成功した場合の報酬が際立たないからだと考えられます.
このため,今回はゴールにより速く辿り着く為のトレーニングと位置づけ,ゴールまでに要したステップ数に応じて報酬が決まる様にしました.
This article is a translation of Japanese ver.
Original ver. is here*1.
Hi, this is chang.
Today I tried to make two agents of artificial intelligence learn bike road race through interactive competitions.
0. Bike road race
Previously, I wrote that goal sprint using slipstream is a typical strategy for winning bike road races*2.
Now I added some keywords for reading this article.
Break
Break is a tactics that one accelerates from the begging of a race and try to keep the gap till the end of the race.
It is often called as "kamikaze" because of its risk
Observe
Riders often observe each other and wait for their goal sprint till just before a goal line.
It is the strategy for letting rivals go sprint before and using slipstream.
At the same time, it avoids rivals not to use slipstream by defending own back.
Bike race is a mental game.
1. Program
I mainly introduced the differences from the previous codes.
(1) Field
Like the previous, race is competed on the image with 32 × 8.
I added the remaining energy bar for competitor.
field
(2) Player(M*cEwan)
I had not changed the rules. Note that today we call the player as "M*cEwan."
Player. We call it as M*cEwan
actions of 4 patterns
1 sprint consumes 1 energy
If remaining energy is 0, sprint(0) is the same to go straight(2)
Initial energy is 5
Big motion with 2 pixels to the lateral directions are set for generating the tactics of chasing the back of rivals.
M*cEwan type: weak in long sprint(=small initial energy) but good at quick action(=big lateral move)
(3) Competitor(P*tacchi)
It is almost the same to the pervious.
One difference is deciding actions using Q value not random value.
Now we call it as "P*tacchi."
Competitor. We call it as P*tacchi
actions of 4 patterns(randomly selected)
1 sprint consumes the 1 energy
If remaining energy is 0, sprint(0) is the same to go straight(2)
Initial energy is 6
P*tacchi type: Large body(=small lateral move) and good at long sprint(=large initial energy)
Note: I changed the reactions to the left and right edge(=wall) because players tended to stick to the walls and neglect lateral motions.
I connected the both edge like ring.
If a player tries to move against the walls, he will fly to the opposite.
I had tested a program to stop players if he collided to the walls but it did not work well.
For players it was so hard to learn both avoiding crash and sprinting against rivals.
(4) Slipstream
I imitated slipstream using simple rules.
The slipstream previously worked only on player but today works on both player and competitor.
Imitated slipstream
(5) Reward
Win: 1.0
Lose: -1.0
I used the all or nothing concept like the previous.
If drawn, rewad is the same to lose(=-1.0).
2. Result
There were great valuation in the results because the player and competitor interactively learned.
So I comprehensively analyzed the 15 cases obtained with the same learning conditions.
Case
M*cEwan(Player)
P*tacchi
Win count
0
break
goal sprint
41
1
/
goal sprint
2
2
break
goal sprint
30
3
observe
observe
63
4
goal sprint
break
68
5
observe
observe
30
6
observe
/
89
7
observe
own pace
37
8
observe
own pace
29
9
/
own pace
5
10
/
break
3
11
observe
own pace
20
12
observe
observe
40
13
break
goal sprint
50
14
break
own pace
0
The table above shows the results.
The win count shown at the right edge are the count of M*cEwan's wins in 100 races using obtained neural network.
In total, M*cEwan won 507 in 1500 races.
The result shows that P*tacchi, whose initial energy is larger, was quite advantageous.
I showed gif animations of typical patterns.
Case 3. M*cEwan(yellow)' signature: Using slipstream and attacking from the back of rivals
Case 11. P*tacchi(blue)'s signature: Keep own pace without lateral meandering.
Case 13. P*tacchi(blue) caught M*cEwan(yellow) in break away
Case 14. P*tacchi(blue) completely defeated M*cEwan(yellow) in hesitated break away
Here, I picked good examples.
If you want to whole results, please look at *3.
2. 1 Strategy
I analyzed the strategy of M*cEwan and P*tacchi, respectively.
M*cEwan selected goal sprint after observing in 7 cases.
M*cEwan had to let rivals go and make use of slipstream, because his power(=initial energy) was smaller than the rival.
Robbie MacEwan in real was also a clever rider who was good to use rivals' efforts.
On the other side, P*tacchi often selected "own pace strategy:" go straight without meandering and sprint after the middle of races.
In other words, he sprinted from his distance without observing rival's move.
In today's game, if the both used their energies up and reached the goal without slipstream, P*tacchi was necessary to win.
For P*tacchi, all have to do is refraining dash in the early part of races to make M*cEwan not take his wheel.
I did not noticed it when I wrote the codes.
To be honest, I felt like to be pointed bugs out by AI, ha ha...
2. 2 Break
It was a little surprise that both M*cEwan and P*tacchi selected break in multiple cases.
In case 1 and 10, P*tacchi won with a probability close to 100% because M*cEwan gave up.
I wonder if M*cEwan could not learn the risk of rival's break...
In case 0, 2, and 13, in which M*cEwan went break, the number of wins for both sides tended to be imminent.
For M*cEwan, going break for getting 50/50 wining rate could be valuable because of his smaller power.
I think it's like a puncher-type rider who isn't suitable for a bunch sprint and tends to escape.
In total, I can say that ”break is valuable because rivals can be dull, especially if you have sustainable power.”
Note that break with hesitation is the worst.
Please look at the gif animation of case 14.
In this case, M*cEwan could not get a single win.
It shows that "if you attack, do not look behind."
3. Afterward
It was interesting.
Next time, I will try more complex competition with increased players.